🌟 Hugging Face Evaluation Guidebook for Large Language Models
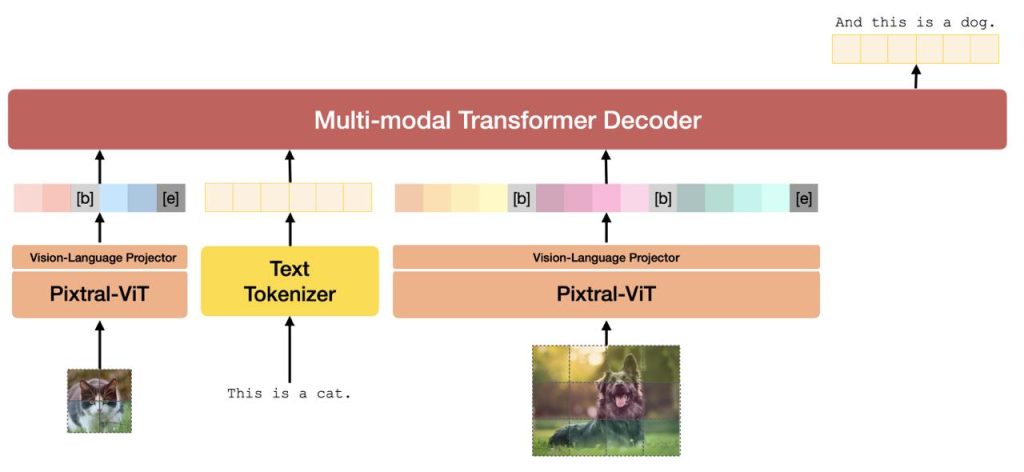
Hugging Face has released a guide on GitHub for evaluating LLMs.
It compiles various methods for evaluating models, guidelines for developing your own evaluations, as well as tips and recommendations from practical experience. The guide discusses different ways of evaluation: using automatic tests, humans, or other models.
Special attention is given to how to avoid issues with model inference and make the results consistent. The guide offers advice on how to clean data, use prompts for communicating with LLMs, and analyze unexpected poor results.
If you’re new to evaluation and benchmarking, you should start with the Basics sections in each chapter before diving deeper. In the General Knowledge section, you’ll also find explanations to help you understand important LLM topics, such as how model inference works and what tokenization is.
More practical sections include: Tips and Tricks, Troubleshooting, and sections dedicated to Designing Evaluation Prompts.
▶️Table of Contents:
🟢Automatic Benchmarks
🟢Human Evaluation
🟢LLM as a Judge
🟢Troubleshooting
🟢General Knowledge
📌 Future Guide Plans:
🟠Describing automatic metrics;
🟠Key considerations when designing a task;
🟠Why LLM evaluation is needed;
🟠Why comparing models is difficult.